In today’s post, we will be advising against storing back-pointers in objects. This is something that we can find in our code, and which unfortunately leads to bugs, decreased performance, code that is harder to reason about and cannot be used in generic algorithms such as the STL ones.
We will first describe these numerous drawbacks in details. Then we will look at an example, which illustrates how back-pointers are typically introduced in production code – often by a developer that felt like there was no other choice – and how to get rid of them.
This small design guideline is not a rule, nor does it apply to all situations. But following this guideline will usually helps making our C++ code simpler, more composable, easier to evolve and to reason about.
The guideline in details & its scope
Objects should not contain back-pointers to an object that owns them (a containing object) directly or indirectly, or to any sub-part of an object that owns them.
Formally: Given an object a which contains and owns an object b, b should not point back to its containing object a, or to any other object c owned by a (with a, b and c potentially being of the same type).
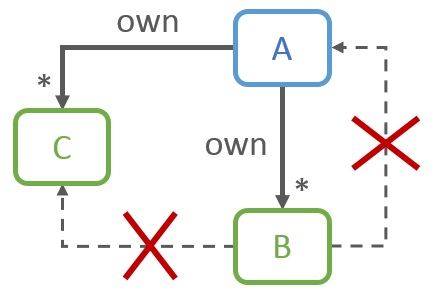
Scope: Following this guideline is not necessarily as long as the objects holding back-pointers are hidden from the outside world, completely encapsulated in a limited scope. Back-pointers become an issue when they leak into the outside world and become everyone’s problem.
For instance, it is perfectly fine for the nodes of a Red-Black Tree to pointer back to their father node. These nodes are typically an implementation detail buried deep in the RBT implementation, hidden from the user.
Generalization: This guidelines generalizes to “avoid cyclic dependencies”, a well known and widely accepted guideline. We will however just focus on back-pointers today, for this anti-pattern occurs very frequently in our code, because it is often felt as being justified or unavoidable.
Rationale & Example
Back-pointers greatly increases the complexity of our code, and typically cause us tons of bugs. Let us see why in details by exploring a reduced example.
Typical example
We have a concrete class Trade which is made of (owns) a bunch of financial Flow (which describe the exchanges of financial instruments that are part of the contract).
| class Flow { /* ... */ }; | |
| class Trade { | |
| //... | |
| private: | |
| std::vector<Flow> m_flows; | |
| }; |
A new requirement requires us to generate payments out of these financial flows. To generate a payment from a flow, we must use the settlement instructions that are stored (for the sake of this example) in the trade owning the flow. This is an important rule we must comply with.
Genesis of a back-pointer
The developer X goes into the Flow class and adds a pay member function to generate a payment, for it seems the most “natural” place to add it (we will look at “why” later in the article).
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| class Flow { | |
| public: | |
| Payment pay() const; | |
| private: | |
| //… | |
| }; |
The developer X also wants to ensure that the settlement instructions used by the pay member function are the one of the trade. He/she reasons that the pay member function should consequently not accept settlement instructions as parameter.
Instead, the flow will now point back to the trade owning it, and this back-pointer will be used to retrieve the appropriate settlement instructions inside the pay member function:
| class Flow { | |
| public: | |
| Payment pay() const { | |
| m_trade->settlementInstructions(); //Do stuff with it | |
| //... | |
| } | |
| private: | |
| Trade* m_trade; | |
| }; |
A back-pointer from the flow to the trade has now been introduced. Let us see why this is a terrible idea, from the least annoying to the most annoying problems it causes.
Tricky rewiring business
The first main issue has to do with correctness. It is really easy to mess up with the back pointer itself, as we often have to rewire the flow to its appropriate Trade instance.
For instance, copying a Trade requires to rewire the Flow instance of the new Trade (every time we move away from the default copy constructor, we should ask ourselves some questions):
| class Flow { | |
| public: | |
| void setTrade(Trade* t); | |
| // ... | |
| }; | |
| class Trade { | |
| public: | |
| Trade(Trade const& other) : m_flows(other.m_flows) | |
| { | |
| for (auto& flow: m_flows) | |
| flow.setTrade(this); | |
| } | |
| // ... | |
| }; |
This introduces correctness issues, since every piece of code that deals with Flow will have to care about correctly rewiring flows to keep them valid. In the long run, the probability of introducing bugs due to this complex rewiring will rise to certainty.
Inhibiting the use of powerful abstractions
The second issue has to do with needless specificity. Because of the back-pointer, adding a Flow instance to an existing trade (for instance to transfer it between trades) requires to rewire it to the new trade:
| class Trade { | |
| public: | |
| void add(Flow const& flow) | |
| { | |
| Flow newFlow = flow; | |
| newFlow.setTrade(this); | |
| m_flows.push_back(std::move(newFlow)); | |
| } | |
| private: | |
| std::vector<Flow> m_flows; | |
| }; |
This introduces needless specificity. Flows became special (*) the moment we added the back-pointer in them. They are not like other values anymore. They need special care.
This for instance means we have to write additional code to wrap any interaction with the most powerful sets of abstractions available in C++, the STL:
- We have to wrap push_back inside a add member function
- We would have to wrap std::copy to transfer flows between trades
- In general, we cannot use the STL directly as our type is special
This kind of specificity should be avoided when possible in our code-bases, for they destroy our ability to factorize code behind powerful abstraction, and are responsible for the uncontrolled growth of our software.
(*) Here “special” refers to the flow not being a value type. It depends on the trade it belongs to and is aware of the hierarchy it belongs to (through the back-pointer). It cannot be manipulated like a simple std::string anymore.
Aliasing kills local reasoning
The next issue has to do with hidden dependencies and aliasing. The flow now aliases the trade which owns it. It can therefore access the trade and all the other things it contains. This decreases our ability to understand and reason about the code.
For instance, our pay member function could use the trade to access the other flows of the trade. The result of calling pay might therefore depend on:
- The presence and value of other flows in the same trade
- Whether the flow is correctly inside a trade or not, etc
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| class Flow { | |
| public: | |
| Payment pay() const | |
| { | |
| for (auto& siblings : m_trade->flows()) { | |
| // … Enjoy accessing / modifying the other flows … | |
| } | |
| } | |
| private: | |
| Trade* m_trade; | |
| }; |
Because of this bidirectional coupling (*), testing becomes harder for our Flow class:
- Instantiating a valid Flow now requires a Trade to be instantiated as well
- The Flow unit test can now be impacted by a modification of the Trade class
(*) We effectively have one component instead of two independent components, as the trade and the flow are so much coupled together that they go together. At this point, the best thing is probably to admit it and be honest with it by putting these two classes in the same header file.
Various performance hits
Because the Flow class is now responsible for managing and maintaining a pointer to its containing Trade, some additional rewiring work needs to be done each time we std::move a Trade instance. The complexity of std::move grows from being constant to being linear in the number of flows.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| class Trade | |
| { | |
| public: | |
| Trade(Trade&& other) | |
| : m_flows(std::move(other.m_flows)) | |
| { | |
| for (auto& flow: m_flows) // O(N) complexity | |
| flow.setTrade(this); | |
| } | |
| private: | |
| std::vector<Flow> m_flows; | |
| }; |
What seemed at first a negligible rewiring logic effectively degrades the performance of a std::move as to making it almost as slow as a full copy of the Trade.
“Interesting” Headaches
Back-pointers also create some “interesting” questions. These questions come with the risk of getting them wrong and headaches due to endless discussions with other developers not agreeing with your choices.
For instance, how should the operator== on the Flow class behave regarding the Trade pointer? There are three choices for the comparison:
- Compare the value of the pointed Trade: it leads to an infinite loop
- Compare the Trade pointer value: we loose value semantic for pointer semantic
- Ignore the Trade pointer value in the comparison: we loose referential transparency (*)
My personal choice would be option 3, but in truth, none of these choices are really appealing. And there are some other annoying questions in store, such as:
- Can we construct a Flow without a Trade? Should it have a default constructor?
- Should we copy the Trade pointer when copying or assigning flows?
We can reason our way out of these questions, but our best answer would rather not to have to answer these questions at all. We are not paid to solve puzzle we create for ourselves.
(*) Two “identical” trades (where identical is defined using ==) might lead to different payments being generated, as the Trade is not taken into account inside the equality check.
Fixing it & Avoiding it
Let us now revisit our previous example of Trade and Flow. We will see how we can avoid back-pointers entirely and all the issues it causes by reworking our design.
Identifying the misconceptions
The way we can fix these issues is by first making sure they are not introduced in the first place. So let us revisit the reasons why the developer X felt there was no other way but to use back-pointers.
Considering objects as real world models. The developer X heard the requirement “a flow should generate its payment using the settlement instructions of the trade it belongs to” and turned:
- The term “generate payment” into a member function
- The term “belong-to” into a back-pointer
But in general, our objects should not be based on an analogy with the real world. Our vocabulary or our bounded contexts may be based on use cases, but no use case does require a member function to be added inside a class.
The same requirement could have come under the form “a trade should generate one payment for each flow it contains”: it would not have meant “add pay member function in the Trade class”.
Over-constraining the problem. The developer X wanted to make sure the payment is generated using the settlement instruction of the trade the flow belongs to, but over-generalized it:
- The rule should have been enforced at the level of the settlement service only
- It was instead promoted as an invariant of Flow class
This is over-constraining the problem. It causes rigidity and difficulty to implement other use cases. For instance, simulating a payment with different settlement instructions than the ones of the trade owning the flow gets harder to implement. Writing unit tests as well.
Encapsulating the data of the Flow class. The developer X wanted to follow the principles of data encapsulation, and added pay as a member function to avoid having to publish some data of the Flow class.
But this is misguided. Encapsulation is meant for implementation details, hiding from the user of an API choices and details we might want to change in the future. It is not really useful as a mechanism to hide the data our information system is fundamentally responsible for managing and transforming.
This data is not a detail. Hiding it only makes our job harder. It might also bring too much responsibilities inside the class. We will come back to this in future articles.
The solution
Once we get rid of the misconceptions which initially lead developer X to add a new member function pay in the Flow class, we can simplify our design quite a bit. We can simply create a free function named pay, taking as parameter a flow and some settlement instructions (*):
| // Free function with less dependencies (no Trade) | |
| Payment pay(Flow const&, SettlementInstructions const&); |
How then do we ensure the rule that the payment is generated using the settlement instructions of the trade the flow belongs to? By construction.
We create a function that calls pay with the appropriate settlement instructions for each flow. This function can for instance take the trade as parameter, and scan the flow.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| std::vector<Payment> generatePayments(Trade const& trade) | |
| { | |
| std::vector<Payment> payments; | |
| for (Flow const& flow: trade.flows()) | |
| payments.push_back(pay(flow, trade.settlementInstructions()); | |
| return payments; | |
| } |
We could do something more elaborate: take several trades, use ranges, aggregate payments, etc. But the basic idea is to enforce and encapsulate our rule in a function, instead of forcing the whole world to know about it (and deal with it by constantly rewiring flows to trades).
(*) Which is less dependencies that a full trade. Recall that the Trade holds the settlement instructions.
What we gained
We previous had multiple places in which we had to maintain an rule by rewiring back-pointers. The rule that was specific to a service was promoted as an invariant of the Flow class. Now we just have one place in which the rule is enforced. As a consequence, the code is:
- More cohesive: the rule is not spread around through obscure back-pointer rewiring
- More generic: the move and copy are standard again, the STL is available
- Easier to reason about: no more aliasing issues to mess with our brain
- More efficient: the std::move takes constant time again
- Not over-constrained: our rule is not imposed on everyone anymore
In short, by reconsidering the problem differently, we got rid of undesired constraints. This allowed us to go for a simpler and less constrained solution. In the process, we earned back a bunch of IQ points, not wasted anymore on a puzzle we created for ourselves.
Conclusion, and what’s next
Back-pointers are very often the indicators of a misconceived problem. Although we cannot always avoid them, we should think twice before introducing them. Doing so might help us identified design mistakes, or latent misconceptions lurking in our mind, to get rid of them and find another way to solve our problem.
Sometimes though, the solution without back-pointers might not be without drawbacks either. It is important then to know and seriously consider the many problems back-pointers introduce in our code – bugs, performance issues, rigidity and needless specificity – and reduce their impacts by encapsulating them.
In future posts, we will tackle similar over-constraining solutions and misconceptions, and discuss ways to avoid them altogether to simplify our code.
Follow @quduval

A pointer with a strong and weak count (such as Rusts weak poiter) can often solve cyclic references and backpointing.
LikeLike
Not sure why a unary Flow ctor taking a Trade wasn’t used to deal solve the specificity problem. With that ctor, all stl algorithms would work again.
LikeLike
Hi Damien, and thank you for the comment 🙂
I will try to answer your remark the best I can.
The article does not show the full implementation of the Flow class, but you can imagine it had an `explicit Flow(Trade*)` constructor, initializing the `m_trade` back-pointer in the flow.
This however does not really solve the problem.
The Flow still has a back-pointer to the Trade, and its behavior will still be affected by it. The aliasing issues are still there. The rewiring logic is still there. The Flow is not a proper value type still: its validity does not only depends on itself but on an external Trade to exist.
While this does not forbid us to use the STL on it (we can use `push_back`, this is fine), there will be plenty of cases in which we will need to wrap the interactions with the STL to deal with the rewiring.
For instance, we still need to worry about rewiring the flows to the appropriate Trade when we std::move them from one Trade to another, or transfer them from one Trade to another.
LikeLike